プレゼン能力の向上に
Teams/Streamの文字起こしで
あなたの口ぐせをチェックする
公開日
はじめに
Teams会議の文字起こし記録(トランスクリプト)機能は便利ですね。その使い方については、以前こちら👇でお伝えしました。
たとえ会議で設定し忘れたときでも、あとからStream上でトランスクリプトを生成出来るコトにも触れました。
https://www.kmds.jp/pc_kowaza/15-teams-autorecord-caption/
【Teams】自動録画設定・動画の期限・字幕と文字起こし
【Microsoft Teams】自動録画設定・動画の期限・字幕と文字起こし 公開日 すっかり定着したMicrosoft Teamsですが、会議を録画できることはご存知だと思います。そこで、…

あとで検索できますし、最近では文字起こしテキストを生成AIに要約させることも出来ます。
このようにトランスクリプト機能はまあまあ使えますが、問題もあります。
今回は、先にその問題を説明したうえで、それを逆手に取った活用方法をご紹介しましょう。途中、RPAのPower Automate for desktop(PAD)を使います。
Teams日本語トランスクリプトの問題点(つなぎ言葉)
まずは問題点から。
現時点(23年11月)で、Teams/Streamによる日本語文字起こしの大きな問題の一つは、つなぎ言葉(フィラー = Filler)ですね。
フィラーとは、「えっと」「あのー」「まあ」などのような、間を埋める場つなぎの言葉です。
日本語の場合、これらがそのままトランスクリプトに反映されてしまいます。
あまりに多発していると、結構読みにくいです。

ちなみに、英語でトランスクリプトを録ってみると、”umm…” といった言い淀みは無視してくれます。英語と比較すると、日本語に関する性能はまだまだなんだなと感じます。
加えて日本語の場合、文字起こし精度自体もそこまで高いものではありませんよね。
特に、仕事で会議をしていると、業界用語・専門用語・社内略語の類はどうしても出てきます。
が、それらを正しく文字化してくれることは少ないと思います。
例えば、海運に関連する当社では「本船動静」という言葉はごく日常的なものです。
しかし、「ほんせんどうせい」と発音しても、文字起こしで正しい漢字になることは極めて稀です。
結局、きちんとしたものを作るためには、VTTファイルをダウンロードして、手作業でかなりの修正を加えないといけないのが現状です。
(面倒なので、実際はそこまでやらない・・・)
これに比べると、OpenAIのWhisperによる文字起こし + 生成AIによる補正プロンプト の組み合わせを使うと、日本語でもフィラーを飛ばした大分 質の高い文字起こしが出来ます。
ですから、最近ではこれがおススメなのですが、誰でもパッと使える訳ではない。
なのでやはり、Teams/Stream文字起こしの改善を期待したいところです。
以上が問題点でした。
口ぐせチェッカーとして使う(PADフローの使い方)
フィラーは不要な場つなぎ言葉ですから、プレゼンや発表などでは、なるべく少ない方が良いとされています。
だからこそTeamsの英語トランスクリプトや、Whisperの文字起こしでは、勝手に削ってくれるようになっているわけです。
しかし理想を言えば、話している時点から、フィラーの回数を少なくしてしまえば良いはずです。
Teamsついでで脱線しますが、私はMicrosoftのSatya Nadellaのスピーチをたまに視聴します。
彼の話し振りはフィラーがほぼなく、淀みなく、全く自然な感じで、すごいなぁといつも感心させられます。
もちろん邪魔にならない感じであれば、つなぎ言葉があっても構いません。
しかし、もしそれによって内容が伝わりにくくなっているとしたら残念なことです。
フィラーを減らすためには、意識したリハーサルが必要でしょう。
なにより、まずどんなフィラーが自分の口ぐせなのかを認識する必要があるでしょう。
そこで、せっかくTeamsトランスクリプトにフィラーが記録されているのを逆に利用して、数えてみようと考えました。
そのために作ったのがこちら👇のPower Automate for desktop(PAD)フローです。
口ぐせの使用頻度チェックだけでなく、トランスクリプトからの口ぐせ除去、さらには用語の置き換えも同時に行います。
コピペしてお使いください。
(PADバージョン 2.37.123.23280で動作確認済み。もしStreamのVTTファイルの形式が変わった場合、エラーになる可能性があります)
**REGION 0. 初期設定。対象となる口ぐせ等を予め登録する
# 👇ここに削除したい口ぐせを登録しておく
SET List TO ['ええと、', 'えっと、', 'ええと', 'えっと', 'えーと、', 'えーと', 'ええ、', 'ええ', 'え?', 'あのー、', 'あのー', 'あの、', 'あの', 'うーん、', 'うーん', 'うん、', 'うん', 'まあ、', 'まあ', 'とりあえず', '一応']
# 👇ここに置き換えたい語と変更後の語を登録する。口ぐせだけでなく、専門用語なども。
Variables.CreateNewDatatable InputTable: { ^['From', 'To'], [$'''ジップ''', $'''Zip'''], [$'''エクセル''', $'''Excel'''], [$'''パークエリ''', $'''Power Query'''], [$'''パワーオートメイト''', $'''Power Automate'''], [$'''KEMDS''', $'''KMDS'''], [$'''エスオーエー''', $'''SOA'''], [$'''エフエックス''', $'''Fx'''], [$'''パワークエリ''', $'''Power Query'''], [$'''kmds''', $'''KMDS'''] } DataTable=> DataTableOriginalWords
**ENDREGION
**REGION 対象ファイルの選択
Display.SelectFileDialog.SelectFile Title: $'''ファイルの指定''' FileFilter: $'''*.vtt; *.txt''' IsTopMost: True CheckIfFileExists: False SelectedFile=> SelectedFile ButtonPressed=> ButtonPressed
IF ButtonPressed <> $'''Open''' THEN
EXIT Code: 0
END
**ENDREGION
File.ReadTextFromFile.ReadText File: SelectedFile Encoding: File.TextFileEncoding.UTF8 Content=> FileContents
Variables.CreateNewDatatable InputTable: { ^['検索語', '出現回数', '出現頻度(1分平均)'], [$'''''', $'''''', $''''''] } DataTable=> DataTable
Variables.DeleteRowFromDataTable DataTable: DataTable RowIndex: 0
**REGION 1.会議時間の割り出し
# 👇正規表現その他で会議の時間を割り出す
Text.ParseText.RegexParse Text: FileContents TextToFind: $'''(\\d{2}:\\d{2}:\\d{2}\\.\\d{3})''' StartingPosition: 0 IgnoreCase: False OccurrencePositions=> Positions Matches=> Matches
SET LastTime TO Matches[Matches.Count - 1]
Text.SplitText.SplitWithDelimiter Text: LastTime CustomDelimiter: $''':''' IsRegEx: False Result=> TextList
SET MeetingHour TO TextList[0] * 1
SET MeetingMinutes TO TextList[1] * 1
SET TotalTime TO MeetingMinutes + MeetingHour * 60
**ENDREGION
**REGION 2. 口ぐせ除去と回数カウント、頻度算出
LOOP FOREACH CurrentItem IN List
Text.ParseText.Parse Text: FileContents TextToFind: CurrentItem StartingPosition: 0 IgnoreCase: False OccurrencePositions=> Positions
Text.Replace Text: FileContents TextToFind: CurrentItem IsRegEx: False IgnoreCase: False ReplaceWith: $'''%''%''' ActivateEscapeSequences: False Result=> FileContents
SET Frequency TO Positions.Count / TotalTime
Variables.TruncateNumber.RoundNumber Number: Frequency DecimalPlaces: 2 Result=> TruncatedValue
Variables.AddRowToDataTable.AppendRowToDataTable DataTable: DataTable RowToAdd: [CurrentItem, Positions.Count, TruncatedValue]
END
**ENDREGION
**REGION 3. 口ぐせ・専門用語や社内用語の置き換え、カウントと頻度算出
LOOP FOREACH CurrentItem IN DataTableOriginalWords
Text.ParseText.Parse Text: FileContents TextToFind: CurrentItem['From'] StartingPosition: 0 IgnoreCase: False OccurrencePositions=> Positions
Text.Replace Text: FileContents TextToFind: CurrentItem['From'] IsRegEx: False IgnoreCase: False ReplaceWith: CurrentItem['To'] ActivateEscapeSequences: False Result=> FileContents
SET Frequency TO Positions.Count / TotalTime
Variables.TruncateNumber.RoundNumber Number: Frequency DecimalPlaces: 2 Result=> TruncatedValue
Variables.AddRowToDataTable.AppendRowToDataTable DataTable: DataTable RowToAdd: [CurrentItem['From'], Positions.Count, TruncatedValue]
END
**ENDREGION
DateTime.GetCurrentDateTime.Local DateTimeFormat: DateTime.DateTimeFormat.DateAndTime CurrentDateTime=> CurrentDateTime
Text.ConvertDateTimeToText.FromCustomDateTime DateTime: CurrentDateTime CustomFormat: $'''yyyyMMdd_hhmm''' Result=> FormattedDateTime
File.WriteToCSVFile.WriteCSV VariableToWrite: DataTable CSVFile: $'''%SelectedFile.Directory%\\%SelectedFile.NameWithoutExtension%_口ぐせ回数_%FormattedDateTime%.csv''' CsvFileEncoding: File.CSVEncoding.UTF8 IncludeColumnNames: True IfFileExists: File.IfFileExists.Overwrite ColumnsSeparator: File.CSVColumnsSeparator.SystemDefault
File.WriteText File: $'''%SelectedFile.Directory%\\%SelectedFile.NameWithoutExtension%_修正後_%FormattedDateTime%.vtt''' TextToWrite: FileContents AppendNewLine: True IfFileExists: File.IfFileExists.Overwrite Encoding: File.FileEncoding.Unicode
Display.ShowMessageDialog.ShowMessage Title: $'''修正修了''' Message: $'''修正が終わりました''' Icon: Display.Icon.Information Buttons: Display.Buttons.OK DefaultButton: Display.DefaultButton.Button1 IsTopMost: False
口ぐせチェッカーフローの使い方
口ぐせと置き換え語の把握
まず、Teams/Streamの文字起こしを眺めて、自分の口ぐせを把握しましょう。
(この把握を、生成AIにやってもらうのもありかもしれませんね。)
私の場合、トランスクリプトを見て初めて気づいたのは、「っていうことですね」を異常なほど多用する点です…。
ひどいときには、「っていうことが言えるっていうことですね」などと喋っており、無駄な引き延ばしのような印象さえあります。まったく無意識なのですが、、、

加えて、うまく文字起こししてくれない用語や固有名詞も把握しておきましょう。
パターンを把握して、用語の置き換えをするためです。
例えば、当社の社名はKMDSですが、KEMDSだったり、ケーエムティーエスだったりと、正しくテキスト化されないことが多いです。
置き換えとは、これらの間違いをKMDSに変更することです。
口ぐせ・置き換え語をフロー変数に登録
コピーしたフローは、PADのデザイナー画面を開いて貼り付けてください。
貼り付けたら、3番目と5番目のアクションを開いて編集します。
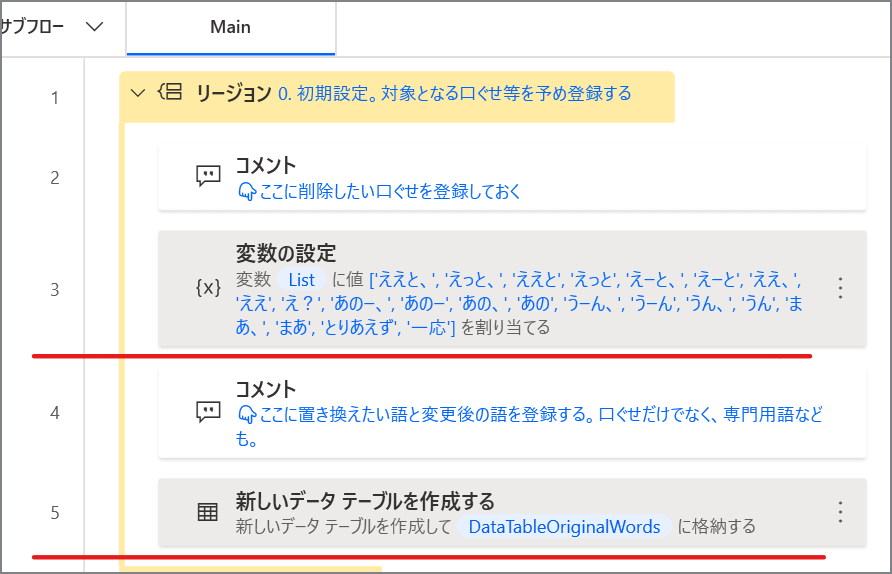
3番目のアクションは、除去したい口ぐせのリストです。
これをダブルクリックして、値の角括弧[ ]内に、カンマ区切りで自分の口ぐせを入れて保存してください。

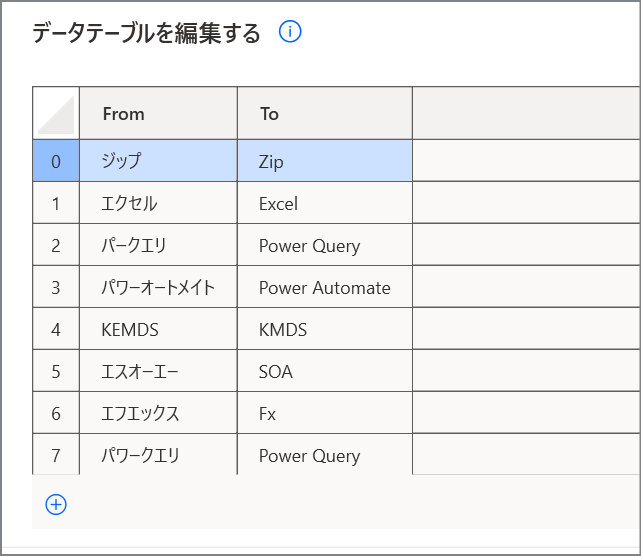
5番目は、置き換え語用のテーブルです。
アクションを開いて、編集からExcelのような一覧が見られますので、Fromに置き換え前の語、Toに置き換え後の語を追加・削除してください。
保存して実行!結果を確認
これで準備OKです。フローを保存して、実行してください。
ファイル選択ダイアログが出てきますので、ダウンロードしたVTTファイルを選んでください。完了メッセージが表示されればお終いです。
元のVTTファイルと同じフォルダに、 元ファイル名 _修正後_日時 というファイル名で新しいVTTファイルが出来ています。
これを確認のうえ、追加のマニュアル修正を多少してStreamに再アップすれば良いでしょう。

同じフォルダには 元ファイル名_口ぐせ回数_日時 というcsvファイルも出来ています。これも見てみます。
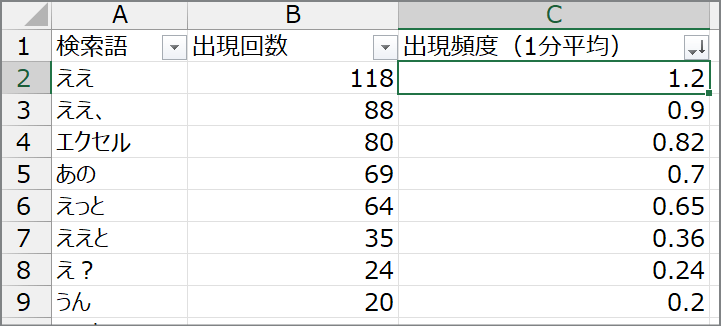
PADフローで除去または置き換えしたそれぞれの語の発生回数と、トランスクリプトの時間から割り出した出現頻度が分かります。
上の図の例では、『ええ』が頻発しているのが見て取れます。
これをチェックすることで、「次回は少しだけ、 『ええ』 を控えるように意識してみよう」といった試みが出来そうです。
おわりに
以上、Teams/Streamのトランスクリプトを利用して、自分の口ぐせの傾向を把握するPADフローの紹介でした。
Microsoftには、日本語文字起こしの精度向上とフィラーの自動除去を是非早くやって欲しいものです。
ただ現状の日本語トランスクリプトは、本来の目的とは離れて、今回のように自分自身のプレゼンテーションのチェック・改善に使えるのでした。
コロナ禍によるリモートワークの影響もあって、Teamsを始めとするWeb会議ツールがずいぶん普及しました。
その過程で、以前はあまりプレゼンテーションをする機会が少なかった人にも、(オンラインとはいえ)複数名を前にして話す回数がむしろ増えているのではないでしょうか。
これまでメールと電話ばかりで仕事をしてきた身には、自分の喋り方・プレゼンの仕方を意識するときが殆ど無かったのでは?とも思います。私自身がそうでした。
その意味でも、Teams/Streamの文字起こし機能やPADフローのようなツールを使って、たまには自分の話し振りをふりかえってみるのも良いでしょう。